Este proyecto se centra en el desarrollo de un sistema de visión por computador para la clasificación de embarcaciones. El objetivo principal es detectar la presencia de barcos en imágenes y determinar si se encuentran atracados o navegando. Presentamos las decisiones tomadas sobre las transformaciones de los datos, arquitectura, hiperparámetros y resultados obtenidos en este trabajo.
1. Metodología
1.1. Preprocesado de imágenes: Data Augmentation
Las transformaciones de los datos se realizaron teniendo en cuenta las características del dominio, entre ellas, giros horizontales, rotaciones de no más de 5 grados, ajustes aleatorios del brillo, contraste y saturación y un desenfoque gausiano. Destacamos RandomCutout una clase creada para cortar aleatoriamente un rectángulo en cualquier parte de la imagen, que no supera un ratio de corte dado. Todas estas transformaciones se aplicaron aleatoriamente mediante el uso de RandomApply.

Figura 1: Ejemplo de imágenes transformadas.
Dado que se utiliza un modelo preentrenado en imágenes de ImageNet, se adoptaron las técnicas de normalización y redimensionamiento basadas en los parámetros de ese conjunto de datos.
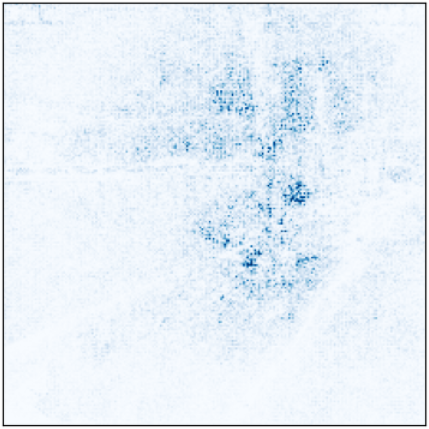
Las decisión de redimensionar las imágenes directamente (teniendo en cuenta la posible perdida de calidad) y no añadirle padding fue debido a que, en los entrenamientos del modelo, este se fijaba en los bordes negros añadidos mas que en la imagen, podemos observar esto con la ayuda de Captum, en la figura 2 mostramos en que regiones el modelo preentrenado sin data augmentation ha prestado mas atención a la hora de predecir una imagen del test (el modelo es el que tiene menos loss del conjunto de validación, en todos los k folds).

Figura 2: Atención en regiones del modelo (con padding).
Y vemos como para el mismo modelo (Figura 3), cambiando unicamente la manera de transformar los datos, vemos que se fija en partes mas concretas de la imagen. Esta aproximación mejora las métricas en el conjunto del test (Tabla 1).

Figura 3: Atención en regiones del modelo (sin padding).
| Métrica | Modelo con Padding | Modelo sin Padding |
|---|---|---|
| Test Accuracy | 0.93 | 0.95 |
| Test Recall | 0.9232 | 0.9375 |
| Test F1 | 0.9287 | 0.9461 |
| Test Precision | 0.9367 | 0.9605 |
| Test AUC | 0.9738 | 0.9905 |
Tabla 1: Comparación de métricas entre modelo con y sin padding.
1.2. Arquitectura de la red neuronal
La arquitectura utilizada es la de MobileNet, una arquitectura no muy compleja. Modificando la última capa para realizar clasificación binaria.
1.3. Estrategias de entrenamiento y validación
Se utilizó la estrategia de k-fold estratificado con k=5, para asegurarnos que los folds mantuviesen una distribución balanceada de clases. Además, se implemento un sampler durante el entrenamiento para equilibrar las clases en cada batch. Se usó la técnica de earlystopping y se almacenó el mejor modelo de cada fold según la métrica de loss.
La selección de estos hiperparámetros dependió fundamentalmente en la inicialización de los pesos del modelo, ya que en los modelos con los pesos aleatorios, la convergencia era mucho mas lenta.
| Métrica | Prentrenado | Pesos aleatorios |
|---|---|---|
| Epochs | 12 | 25 |
| Patience | 3 | 11 |
| Learning rate | 0.001 | 0.01 |
| Optimizer | ADAM | ADAM |
| Criteria | Cross entropy | Cross entropy |
Tabla 2: Hiperparámetros seleccionados
2. Experimentos y Resultados
2.1. Modelo clasificación barco/no-barco
A continuación, presentamos las gráficas de la evolución de las métricas en el conjunto de validación para los cuatro modelos (con/sin data augmentation y con/sin pesos aleatorios).
I. Modelo preentrenado sin data augmentation (preT_wF):
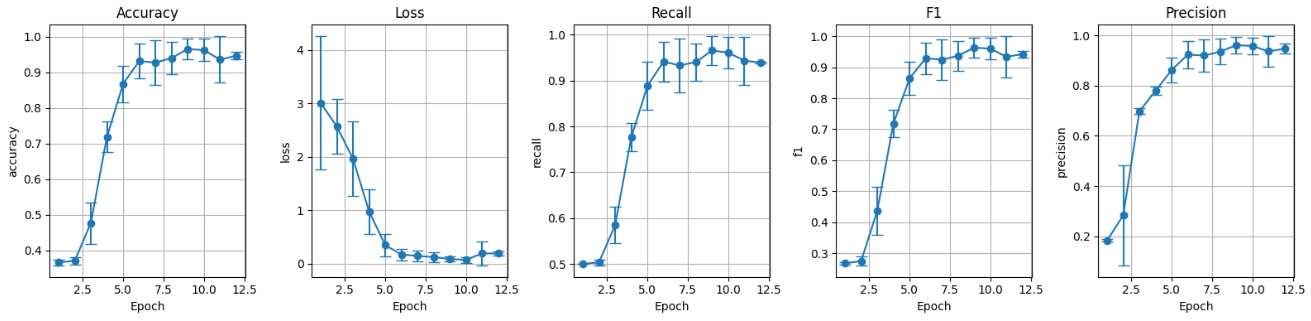
Figura 5: Métricas conjunto de validación preentrenado sin data augmentation.
II. Modelo preentrenado con data augmentation (preT_wT):
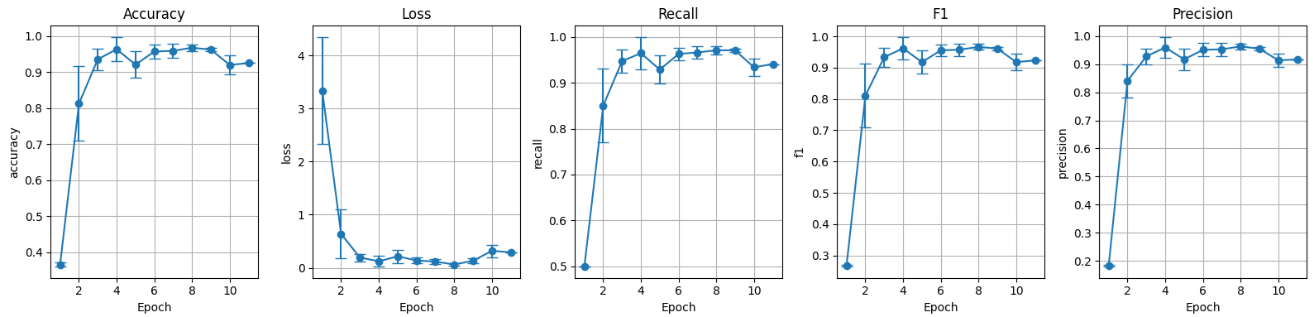
Figura 6: Métricas conjunto de validación preentrenado con data augmentation.
III. Pesos aleatorios sin data augmentation (preF_wF):
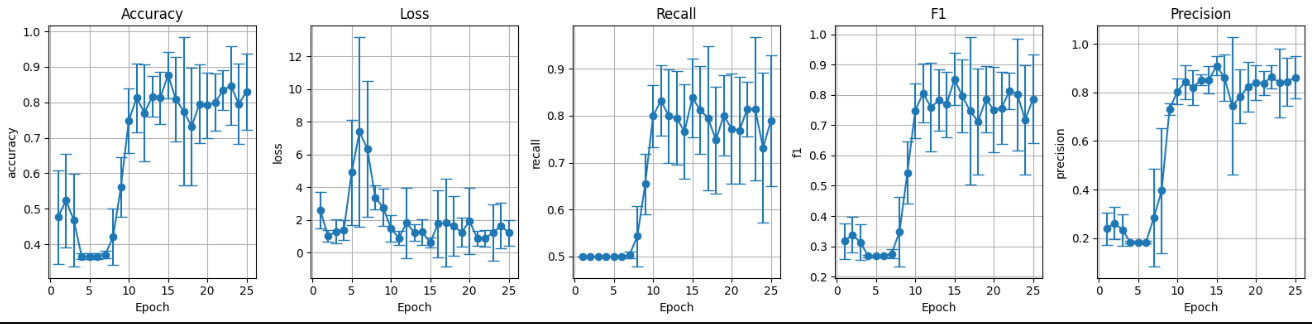
Figura 7: Métricas conjunto de validación pesos aleatorios sin data augmentation.
IV. Pesos aleatorios con data augmentation (preF_wT):

Figura 8: Métricas conjunto de validación pesos aleatorios con data augmentation.
Mostramos las métricas (Tabla 3) y curvas ROC (Figuras 9, 10, 11 y 12) sobre el conjunto de test de los k modelos obtenidos para cada inicialización (como indicamos antes, en cada fold almacenamos el que menor loss obtuviese en el conjunto de validación).
| Modelo | Accuracy µ | Accuracy σ | Recall µ | Recall σ | F1 µ | F1 σ | Precision µ | Precision σ | AUC µ | AUC σ |
|---|---|---|---|---|---|---|---|---|---|---|
| preT_wF | 0.93 | 0.02 | 0.9083 | 0.0250 | 0.9197 | 0.0227 | 0.9446 | 0.0136 | 0.9688 | 0.0116 |
| preT_wT | 0.92 | 0.02 | 0.9092 | 0.0279 | 0.9139 | 0.0225 | 0.9260 | 0.0142 | 0.9805 | 0.0061 |
| preF_wF | 0.85 | 0.03 | 0.8232 | 0.0332 | 0.8354 | 0.0338 | 0.8793 | 0.0311 | 0.8992 | 0.0410 |
| preF_wT | 0.84 | 0.03 | 0.8149 | 0.0322 | 0.8269 | 0.0330 | 0.8752 | 0.0280 | 0.9195 | 0.0190 |
Tabla 3: Media y desviación típica de métricas de mejor modelo por fold en test.
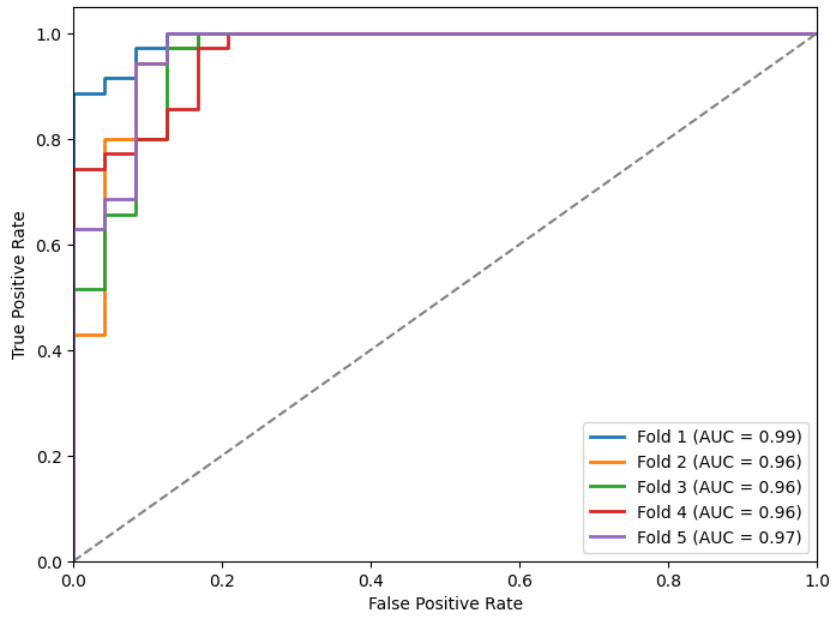
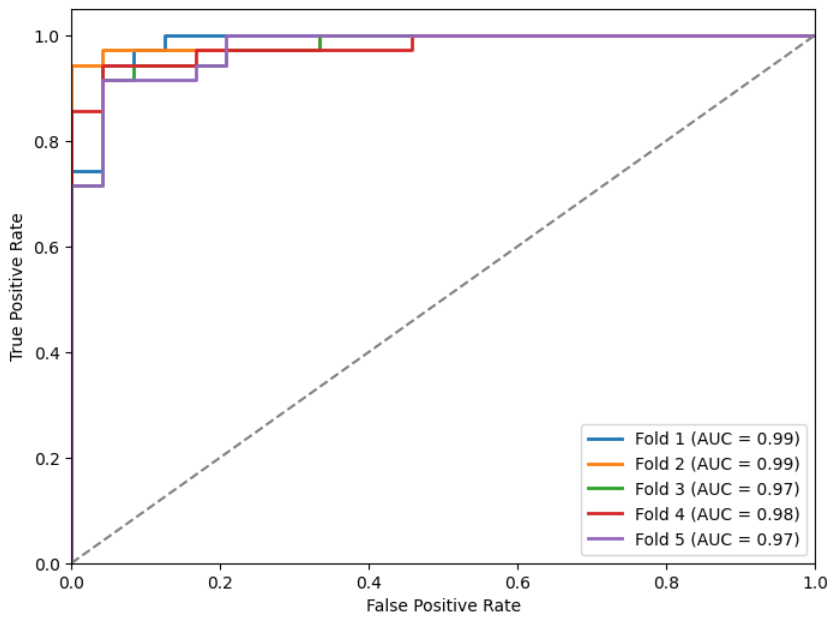
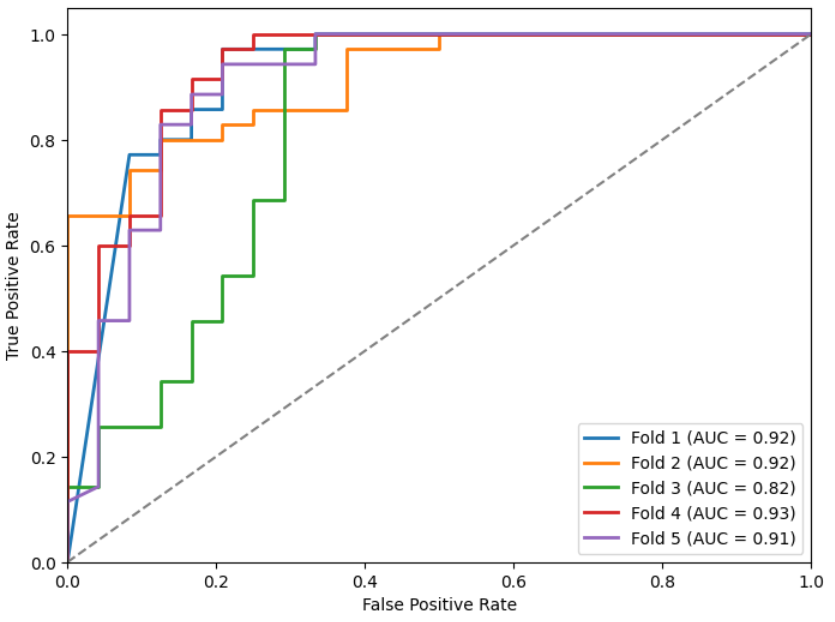
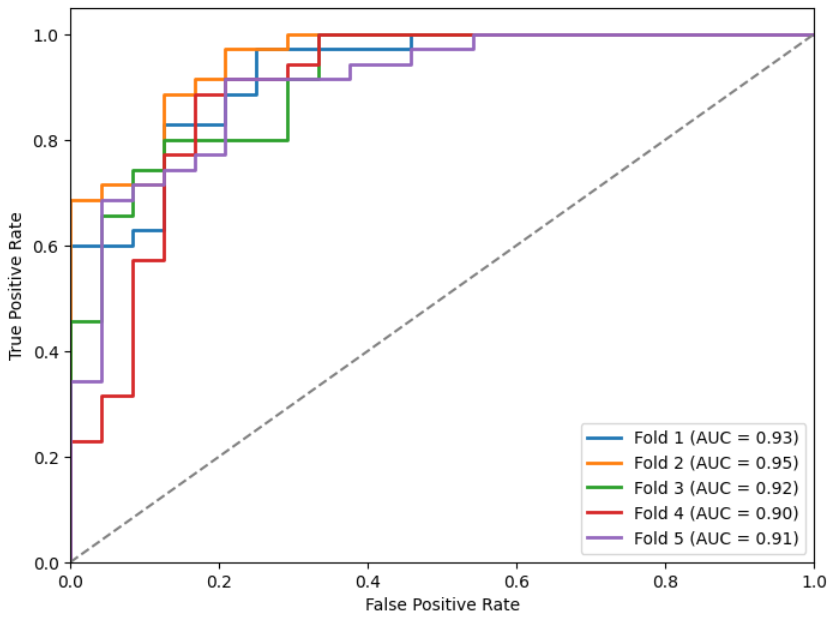
Figuras 9, 10, 11 y 12: Curvas ROC para los diferentes modelos.
Por último, mostramos las métricas del mejor modelo para cada inicialización (entendiendo por mejor, el que menor loss tenga en el conjunto de test, no en el de validación).
| Modelo | Accuracy | Recall | F1 | Precision | AUC |
|---|---|---|---|---|---|
| preT_wF | 0.9492 | 0.9375 | 0.9461 | 0.9605 | 0.9905 |
| preT_wT | 0.9322 | 0.9232 | 0.9287 | 0.9367 | 0.9893 |
| preF_wF | 0.8983 | 0.8750 | 0.8891 | 0.9268 | 0.9333 |
| preF_wT | 0.8644 | 0.8464 | 0.8550 | 0.8731 | 0.9262 |
Tabla 4: Métricas de los modelos
Me parece muy interesante ver como los 4 modelo son capaces de clasificar la Figura 3 mostrada anteriormente correctamente, pero prestando atención a diferentes partes de la imagen.
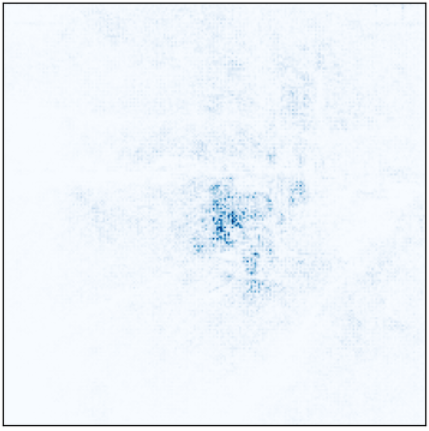
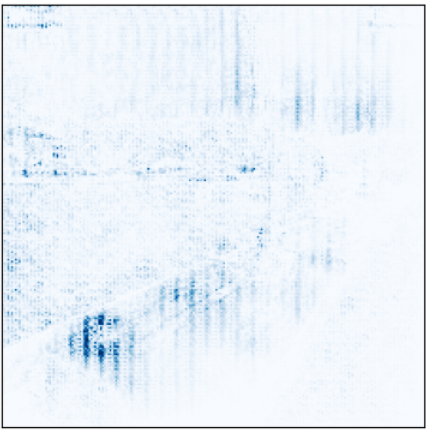
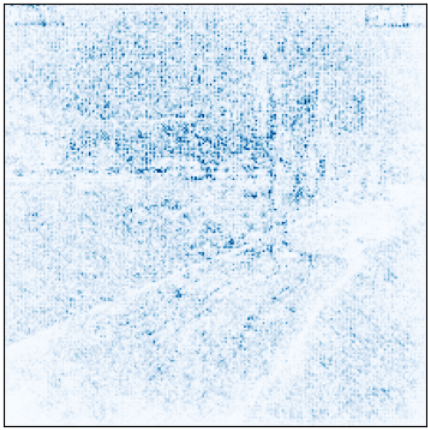
Figuras 13, 14, 15 y 16: Atención de los modelos preT_wF, preT_wT, preF_wF y preF_wT.
2.2. Modelo clasificación barco atracado/no-atracado
Para este modelo, usamos el modelo entrenado previamente que mejor loss obtuvo. Y lo entrenamos siguiendo el mismo proceso, pero, en lugar de 4 modelos distintos, usaremos el ya entrenado con data augmentation.
Métricas del entrenamiento en el conjunto de validación:
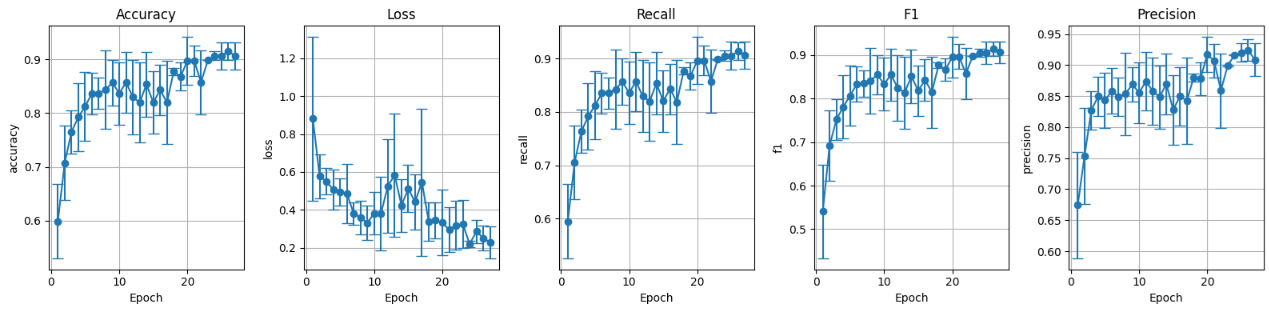
Figura 17: Métricas conjunto de validación preentrenado con data augmentation.
Métricas y curvas ROC sobre el conjunto de test de los mejores modelos por fold:
| Modelo | Accuracy µ | Accuracy σ | Recall µ | Recall σ | F1 µ | F1 σ | Precision µ | Precision σ | AUC µ | AUC σ |
|---|---|---|---|---|---|---|---|---|---|---|
| preT_wT | 0.87 | 0.05 | 0.8687 | 0.0484 | 0.8679 | 0.0496 | 0.8835 | 0.0342 | 0.9427 | 0.0218 |
Tabla 5: Media y desviación típica de métricas de mejor modelo por fold en test.
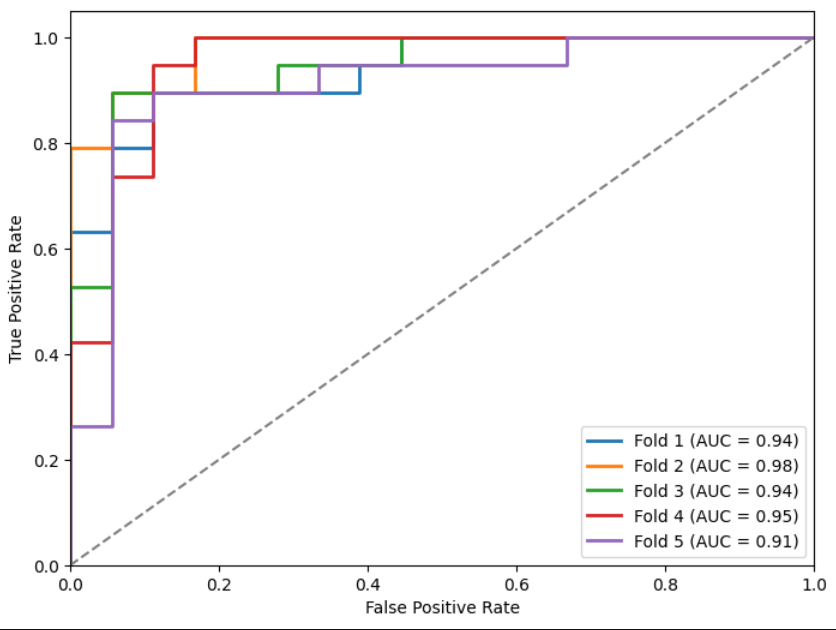
Figura 18: ROC preT_wT.
Métricas del mejor modelo en el conjunto de test:
| Modelo | Accuracy | Recall | F1 | Precision | AUC |
|---|---|---|---|---|---|
| preT_wT | 0.9189 | 0.9196 | 0.9189 | 0.9196 | 0.9766 |
Tabla 6: Estadísticas del modelo preT_wT
Por último, es interesante volver a ver como cambia la atención del nuevo modelo al previo preentrenado:



Figuras 19, 20 y 21: Imagen original, atención modelo preT_wF (barcos) y atención modelo preT_wT (barcos atracados).